Abstract
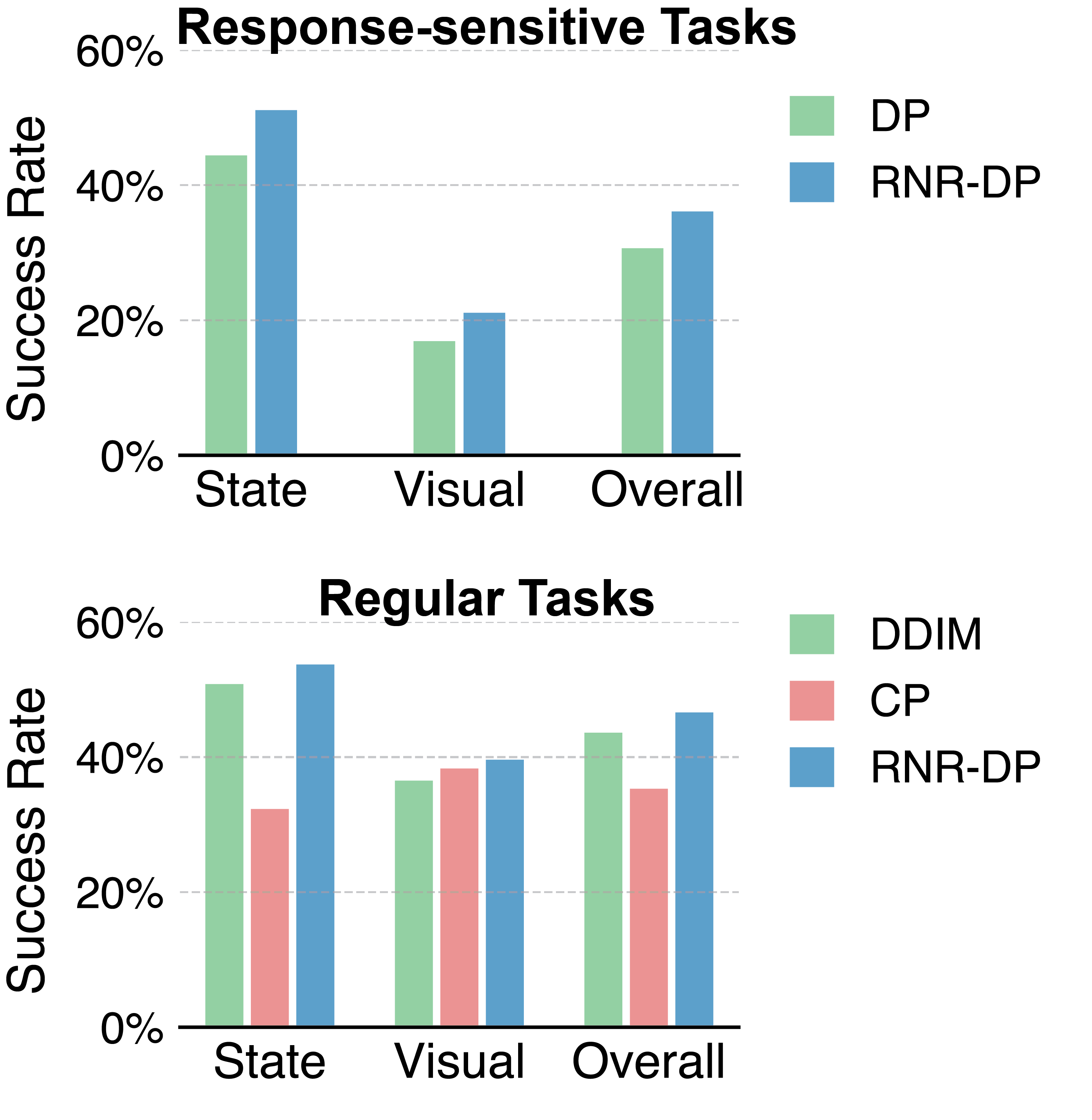
Imitation learning is an efficient method for teaching robots a variety of tasks. Diffusion Policy, which uses a conditional denoising diffusion process to generate actions, has demonstrated superior performance, particularly in learning from multi-modal demonstrates. However, it relies on executing multiple actions to retain performance and prevent mode bouncing, which limits its responsiveness, as actions are not conditioned on the most recent observations. To address this, we introduce Responsive Noise-Relaying Diffusion Policy (RNR-DP), which maintains a noise-relaying buffer with progressively increasing noise levels and employs a sequential denoising mechanism that generates immediate, noise-free actions at the head of the sequence, while appending noisy actions at the tail. This ensures that actions are responsive and conditioned on the latest observations, while maintaining motion consistency through the noise-relaying buffer. This design enables the handling of tasks requiring responsive control, and accelerates action generation by reusing denoising steps. Experiments on response-sensitive tasks demonstrate that, compared to Diffusion Policy, ours achieves 18% improvement in success rate. Further evaluation on regular tasks demonstrates that RNR-DP also exceeds the best acceleration method by 6.9%, highlighting its computational efficiency advantage in scenarios where responsiveness is less critical.
Method Overview
Below is a inference overview of our method. The core of RNR-DP is the noise-relaying buffer and it has 3 stages during the entire control-loop, as exemplified by the transition between time step t and time step t+1, (1) The buffer contains noisy actions with increasing noise levels. (2) After denoising once, each action in the buffer is denoised for one step, clean action at the buffer's head is removed and executed (dequeue). (3) The remaining noisy actions are left shifted for one slot and a fully noisy action is appended to the buffer's tail (enqueue).